There is no bad data, there is only data
Inês and Bryan are members of the Public Health Alliance for Genomic Epidemiology (PHA4GE), a global coalition of public health, academic and industry professionals who aim to document and develop best practices in using genomic sequence data for public health epidemiology.
DNA sequencing is becoming increasingly accessible with the availability of platforms that require a lower initial investment to get started, as well as platforms that generate higher throughput, allowing for lower per-sample costs. Nevertheless, substantial time and money are still required to generate sequence data, and occasionally, the data produced is not always good enough to perform all types of analyses. This can be compounded by the absence of global standards that determine what constitutes ‘good’ data, as these thresholds are often set within organizations based on their own specific needs.
Even when a sequencing run is less than ideal, the sharing of these suboptimal datasets can still aid fields such as public health. For example, whole genome sequences of SARS-CoV-2 that have insufficient coverage of the whole genome can still yield valuable information about the spike protein. Bacterial genomes that were not sequenced deeply enough for phylogenetic analyses could still be used to gain some understanding of its antimicrobial resistance phenotypes. These data can be useful to the community, especially if accompanied by high quality metadata. Sub-optimal data can also be used for training purposes and used to test bioinformatic tools. This can help us understand the range of possible scenarios that could occur with real world data which cannot be easily replicated by data simulated in silico.
In our recent Microbial Genomics publication (June 2024) entitled “PHA4GE quality control contextual data tags: standardized annotations for sharing public health sequence datasets with known quality issues to facilitate testing and training” [1], we show how these so called ‘bad data’ can be made more valuable by tagging them with information about their potential issues. Our proposed way of annotating these data, called QC tags, provides a systematic way of tagging these data with known quality issues, to allow data generators to communicate with data users. QC tags also allow users to search and filter datasets with quality issues, to include and exclude them from their workflow as desired. Our approach leverages ontologies to allow for consistent descriptions of issues that can plague sequence data, aiding reproducibility and clear understanding by data users.
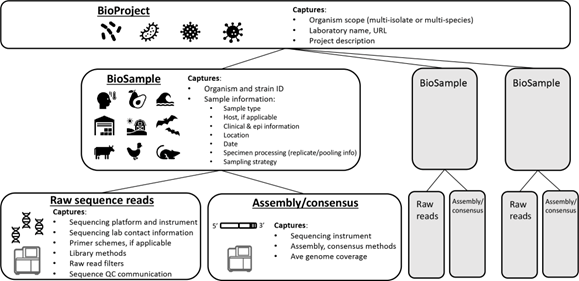
When uploading sequencing data to publicly-available data repositories such as the International Nucleotide Sequence Database Consortium (INSDC), which includes databases such as Short Read Archive (SRA), Biosample and GenBank, QC tags can be added where appropriate. However, when the organization of this data is not standardized, it can be difficult to know where this information can be found. This impacts the utility of data found in public sequence repositories. The Pathogen Data Object Model, proposed in the manuscript published in Microbial Genomics in December 2023 entitled “Putting everything in its place: using the INSDC compliant Pathogen Data Object Model to better structure genomic data submitted for public health applications” [2], unlocks the usability of data. This allows it to be used not just for research purposes, but also for surveillance and public health decision-making by inferring epidemiologically-relevant events based on robust contextual metadata. This common pathogen data structure formalizes the minimum pieces of both sequence and contextual data necessary for actionability.
There is power in data, but a lot of that power comes from being able to place it into the right context. The purpose of sequencing, the sample source and condition and a clear description of methods applied can make data more useful, regardless of its quality. So go ahead, and share your data, even if the ideal scenario was not met. With proper annotation, someone’s bad-quality data might represent an invaluable training opportunity or a tool for the validation of new methods.
References
1. Griffiths EJ, Mendes I, Maguire F, Guthrie JL, Wee BA, Schmedes S, et al.. PHA4GE quality control contextual data tags: standardized annotations for sharing public health sequence datasets with known quality issues to facilitate testing and training. Microbial Genomics. Microbiology Society,; 2024; doi: 10.1099/mgen.0.001260.
2. Timme RE, Karsch-Mizrachi I, Waheed Z, Arita M, MacCannell D, Maguire F, et al.. Putting everything in its place: using the INSDC compliant Pathogen Data Object Model to better structure genomic data submitted for public health applications. Microbial Genomics. Microbiology Society,; 2023; doi: 10.1099/mgen.0.001145.